前一阵,一张集合了20 位“韩国小姐”选美大赛大邱区选手的GIF图(见下)广为流传,世人纷纷震惊于韩国整容技术的高度一致性。有网友称“韩国整容界的混乱终于在这一张脸上体 现出来了”。那么,这20位韩国小姐的脸到底有多相似?让我们用科学的方法来揭开谜底。 
首先,放出20位佳丽集合图,并对她们进行编号(第一列从上往下依次为1-4号,第二列为5-8号,以此类推)。

通过简单的计算摄影学方法,可以将20张图片的特征集合到一张图片上,得出这20位佳丽的“平均脸”。结果如下:
 然后,通过一个视频来观察一下这20张脸的渐变情况,看看每张图片之间的变化幅度。 到目前为止,只能借助上面这些可视化对象进行定性分析,通过主观评价得出结论(结论是像呢还是像呢还是像呢?)。接下来,还需要进行定量分析。 第一步,要构建这些选手面部的“特征空间”。不过,由于选手在拍照时的姿势差异和不同的发型干扰,我们不能用标准的“主成分分析法”(Principle Component Analysis,简称PCA)构建特征空间。因此,需要用一种鲁棒性更强的PCA,来进行脸部图像的低秩部分(low rank part)分解和稀疏误差(sparse errors)分解,如下图中的三个例子所示:
然后,通过一个视频来观察一下这20张脸的渐变情况,看看每张图片之间的变化幅度。 到目前为止,只能借助上面这些可视化对象进行定性分析,通过主观评价得出结论(结论是像呢还是像呢还是像呢?)。接下来,还需要进行定量分析。 第一步,要构建这些选手面部的“特征空间”。不过,由于选手在拍照时的姿势差异和不同的发型干扰,我们不能用标准的“主成分分析法”(Principle Component Analysis,简称PCA)构建特征空间。因此,需要用一种鲁棒性更强的PCA,来进行脸部图像的低秩部分(low rank part)分解和稀疏误差(sparse errors)分解,如下图中的三个例子所示:  **第二步,**通过奇异值分解法(singular value decomposition),可以得到这 20 张脸的“特征脸”以及对应的特征值,从下面这张曲线图中可以看到,没有特征脸的特征值大于等于 7,因此这些图像数据的秩为 6。
**第二步,**通过奇异值分解法(singular value decomposition),可以得到这 20 张脸的“特征脸”以及对应的特征值,从下面这张曲线图中可以看到,没有特征脸的特征值大于等于 7,因此这些图像数据的秩为 6。  将 6 张特征脸图像化如下,其中包含了20张脸部图像的主要变化。
将 6 张特征脸图像化如下,其中包含了20张脸部图像的主要变化。  第三步,将每张脸投影到特征脸上,分析出这些脸部图像在特征空间中是怎样分布的。下图是 20 张脸的特征系数曲线,可以看到,大部分特征差异都集中在前两个特征值上。
第三步,将每张脸投影到特征脸上,分析出这些脸部图像在特征空间中是怎样分布的。下图是 20 张脸的特征系数曲线,可以看到,大部分特征差异都集中在前两个特征值上。 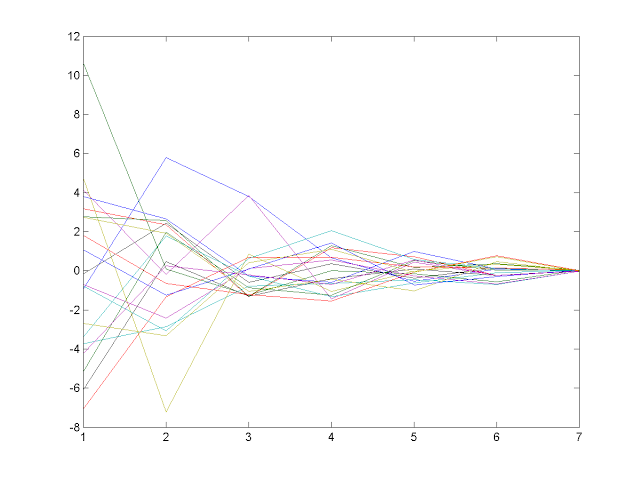 再将每张脸对应前两个特征值的系数绘制成图,就可以看出这 20 位选手的外貌特征有多相似(分布越近的点代表相似程度越高)。
再将每张脸对应前两个特征值的系数绘制成图,就可以看出这 20 位选手的外貌特征有多相似(分布越近的点代表相似程度越高)。  第四步,通过两两对比来比较这些参赛选手互相之间的外貌相似程度。下图中,方块颜色越蓝表示两者越相似,越红表示越不相似。
第四步,通过两两对比来比较这些参赛选手互相之间的外貌相似程度。下图中,方块颜色越蓝表示两者越相似,越红表示越不相似。 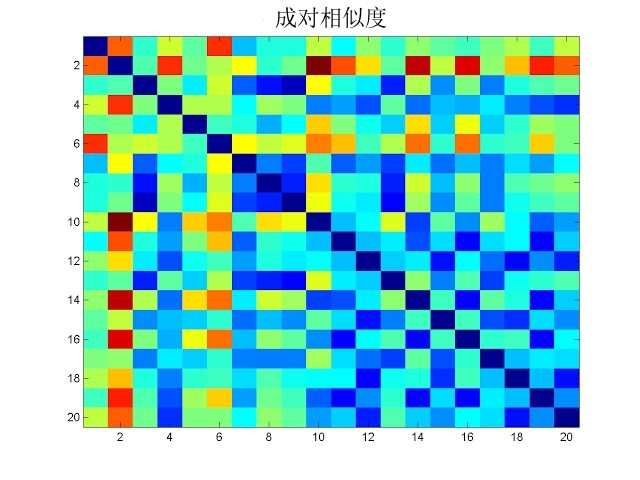 通过对上图的统计,可以得出下面这张横向对比图,横轴代表选手编号,纵轴代表差异程度高低。
通过对上图的统计,可以得出下面这张横向对比图,横轴代表选手编号,纵轴代表差异程度高低。 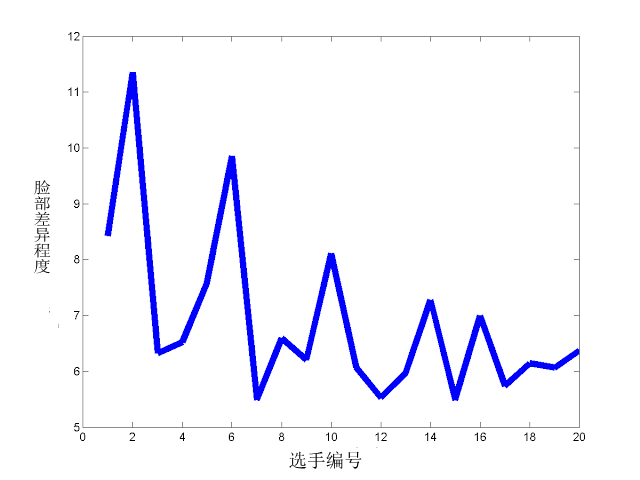 最后,我们可以看到,这20位“韩国小姐”参赛选手之中,与“平均脸”最接近,也就是与其他人长得最像的三位分别是7号、12号和15号选手。
最后,我们可以看到,这20位“韩国小姐”参赛选手之中,与“平均脸”最接近,也就是与其他人长得最像的三位分别是7号、12号和15号选手。  而与其他人外貌相似程度最低的三位分别是 1 号、2 号和 6 号选手。恭喜她们!
而与其他人外貌相似程度最低的三位分别是 1 号、2 号和 6 号选手。恭喜她们!  5月3日,“韩国小姐”大邱赛区的大众投票结果出炉。前五名分别是5号、 1号、 15号、20号与19号佳丽。其中位列二三名的1号与15号佳丽分别在“最相似”与“最不相似”三人组中。这似乎与那个著名的观点“大众脸很吸引人,但最吸引人的却不是大众脸”有所巧合。
5月3日,“韩国小姐”大邱赛区的大众投票结果出炉。前五名分别是5号、 1号、 15号、20号与19号佳丽。其中位列二三名的1号与15号佳丽分别在“最相似”与“最不相似”三人组中。这似乎与那个著名的观点“大众脸很吸引人,但最吸引人的却不是大众脸”有所巧合。  当我们在前两个特征值系数图中找到前五名佳丽(红点标记),可以发现,大众在投票过程中似乎避开了选择互相之间外貌非常近似的佳丽。
当我们在前两个特征值系数图中找到前五名佳丽(红点标记),可以发现,大众在投票过程中似乎避开了选择互相之间外貌非常近似的佳丽。 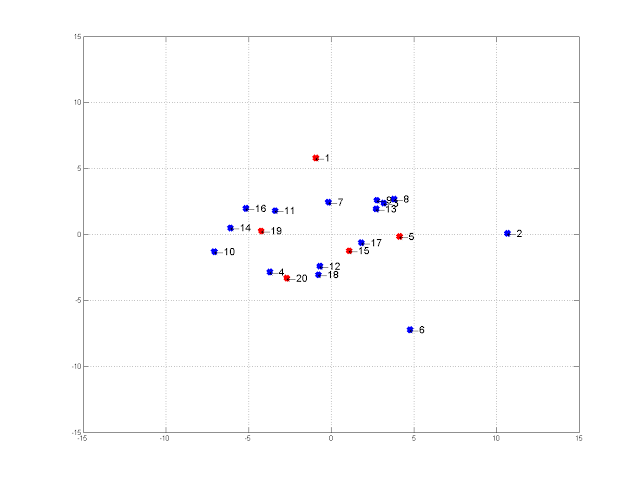 **友情提醒:**整容结果可能跟预期不一致,接受韩式整容需谨慎。 原作者:黄嘉斌 译:小行踪
**友情提醒:**整容结果可能跟预期不一致,接受韩式整容需谨慎。 原作者:黄嘉斌 译:小行踪